Awarie IT zdarzają się każdemu

Od paru godzin trwa awaria komunikatora internetowego Slack. Kilka tygodni temu nie można było korzystać z usług firmy Google, a jeszcze wcześniej spora część Internetu nie działała z powodu awarii usług Cloudflare. Czy to możliwe, że usługi w chmurze są niedostępne?
Spis treści
Niedostępność systemu informatycznego jest rzeczą naturalną i powinniśmy się do niej przyzwyczaić zamiast wierzyć w zapewnienia marketingowe, że usługi w chmurze działają non stop.
Każde zepsute urządzenie techniczne działa poprawnie w obecności wykwalifikowanego personelu naprawczego.
Musimy być przygotowani na takie rzeczy jak awarie w serwerowniach, zalania czy pożary, które mogą zniszczyć całą naszą infrastrukturę serwerową.
Dlaczego systemy IT są niedostępne?
Strona internetowa nie musi być zawsze dostępna, a co więcej jest wiele powodów ku temu, aby nie działała. Aktualizacja oprogramowania samego serwisu lub infrastruktury serwerowej to jedna z głównych przyczyn planowanych niedostępności. Tego typu przerwy w działaniu nie są incydentami, ba są wręcz czymś pożądanym.
Kolejną przyczyną są incydenty, które mimo zapewnienia wysokiego SLA w infrastrukturze, dopuszczają pewną niedostępność. Są to wszelakiego rodzaju awarie związane z błędami w oprogramowaniu, zwiększonym i nieprzewidzianym ruchem na stronie lub uszkodzeniem elementów infrastruktury. Źródłem tych incydentów są problemy.
Spokojnie, to tylko awaria!
Gaszenie pożarów, czyli rozwiązywanie incydentów jest stałym elementem pracy z systemami informatycznymi. Teoretycznie można przygotować taki system IT, który jest odporny na incydenty oraz problemy, ale koszty jego wdrożenia i utrzymania będą kosmicznie wysokie.
Z praktycznego punktu widzenia, lepszym rozwiązaniem jest oszacowanie i przyjęcie strat związanych z incydentem w stosunku to kosztów poniesionych, aby tej awarii uniknąć. Przykładem takim może być sklep internetowy działający na serwerze hostingowy, którego koszt roczny wynosi 200 zł. Jeżeli w ciągu miesiąca na takim sklepie zarabiamy 50 zł, to awaria serwera trwająca ponad godzinę, jest tańsza niż zakup serwerów o większej dostępności.
Natomiast jeżeli na sklepie ma w ciągu godziny obrót rzędu 10000 zł to przestój trwający nawet 30 minut, jest dla nas kosztowny. Wtedy dobrym rozwiązaniem jest zakup infrastruktury serwerowej dużo droższej, o zwiększonej dostępności.
Więcej na temat systemów o wysokim SLA dowiesz się z mojego wykładu na konferencji PHPCon Poland 2019.
Incydent czy problem?
Awarie możemy podzielić na incydenty oraz problemy. Klasyfikację taką przyjmuje się w ITIL (ang. Information Technology Infrastructure Library). Mimo że ten zestaw praktyk wymyślono w latach 80. XX wieku, nadal ma zastosowanie do obecnej rzeczywistości.
Incydent to nieplanowane przerwanie świadczenia usługi lub niedziałanie składnika, który jeszcze nie wpłynął na usługę. Awaria terminala płatniczego w jednym ze sklepów w godzinach jego pracy jest incydentem. Dochodzi do przerwania świadczenia usługi płatniczej. Gdyby taka sytuacja miała miejsce poza godzinami otwarcia sklepu, nie będzie klasyfikowana jako incydent.
Również wszelakie prace planowe, prace konserwacyjne w godzinach świadczenia usługi, nie są klasyfikowane jako incydenty, gdyż nie są nieplanowane.
Incydenty należy rozwiązywać najszybciej jak się da, bez względu na to czy zastosujemy poprawki czy tymczasowe obejście.
Problem jest przyczyną jednego lub większej liczby incydentów. Celem zarządzania awariami jest zidentyfikowanie problemów, aby w przyszłości nie generowały jeszcze więcej takich zdarzeń.
Odwołując się do przykładu z niedziałającym terminalem płatniczym: problemem był błąd w oprogramowaniu tego urządzenia, który powodował jego zawieszenie. Tymczasowym obejściem był restart urządzenia, a poprawką - aktualizacja oprogramowania. Zidentyfikowanie problemu oraz zastosowanie poprawki, gwarantują że podobne incydenty nie pojawią się w innych sklepach.
Awarie u największych
Incydenty czy planowane niedostępności zdarzają się każdemu, nawet największemu dostawcy systemów informatycznych. Każdorazowo o problemach związanych z ich usługami informują na specjalnych stronach internetowych, zwanych status page.
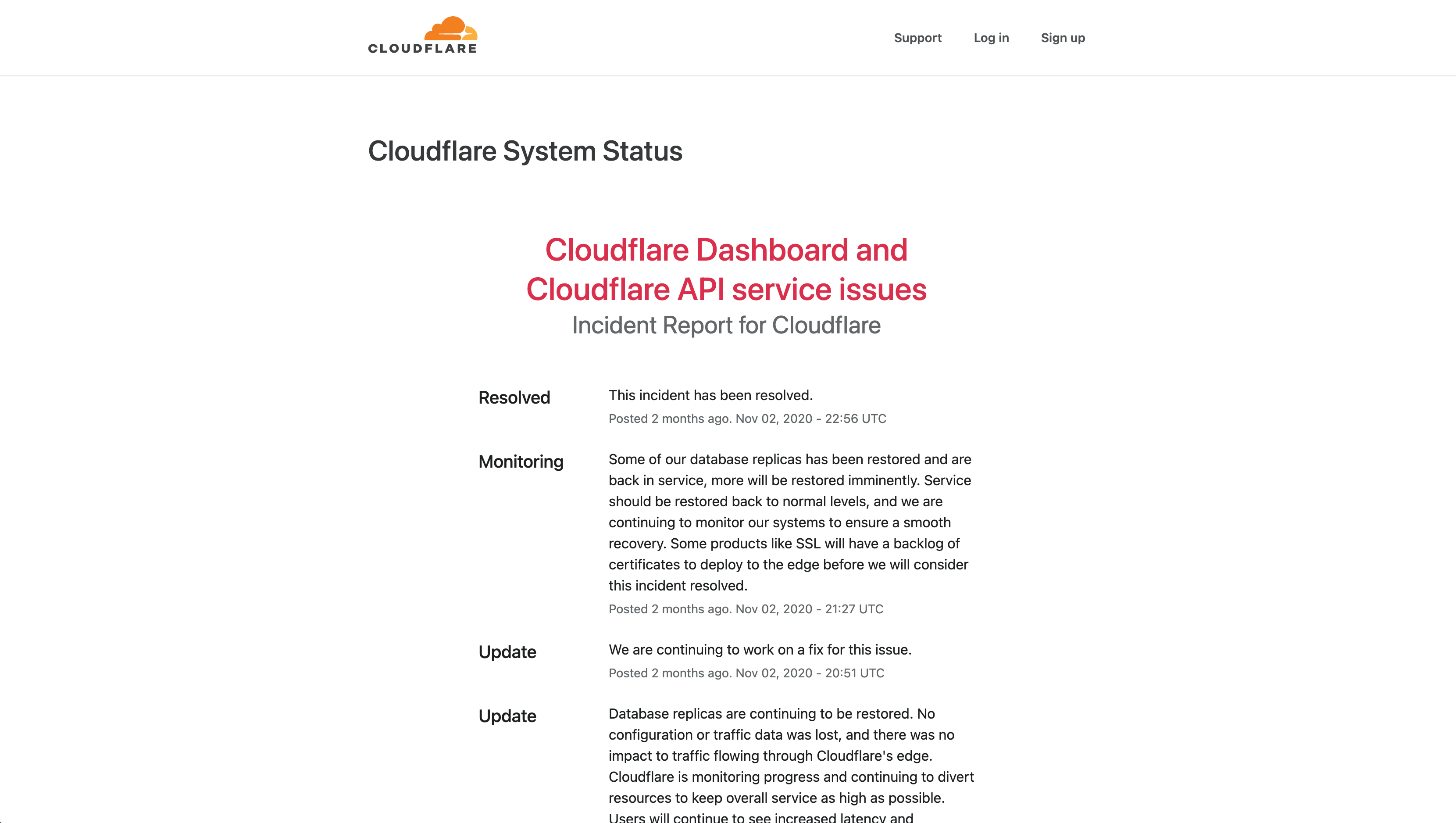
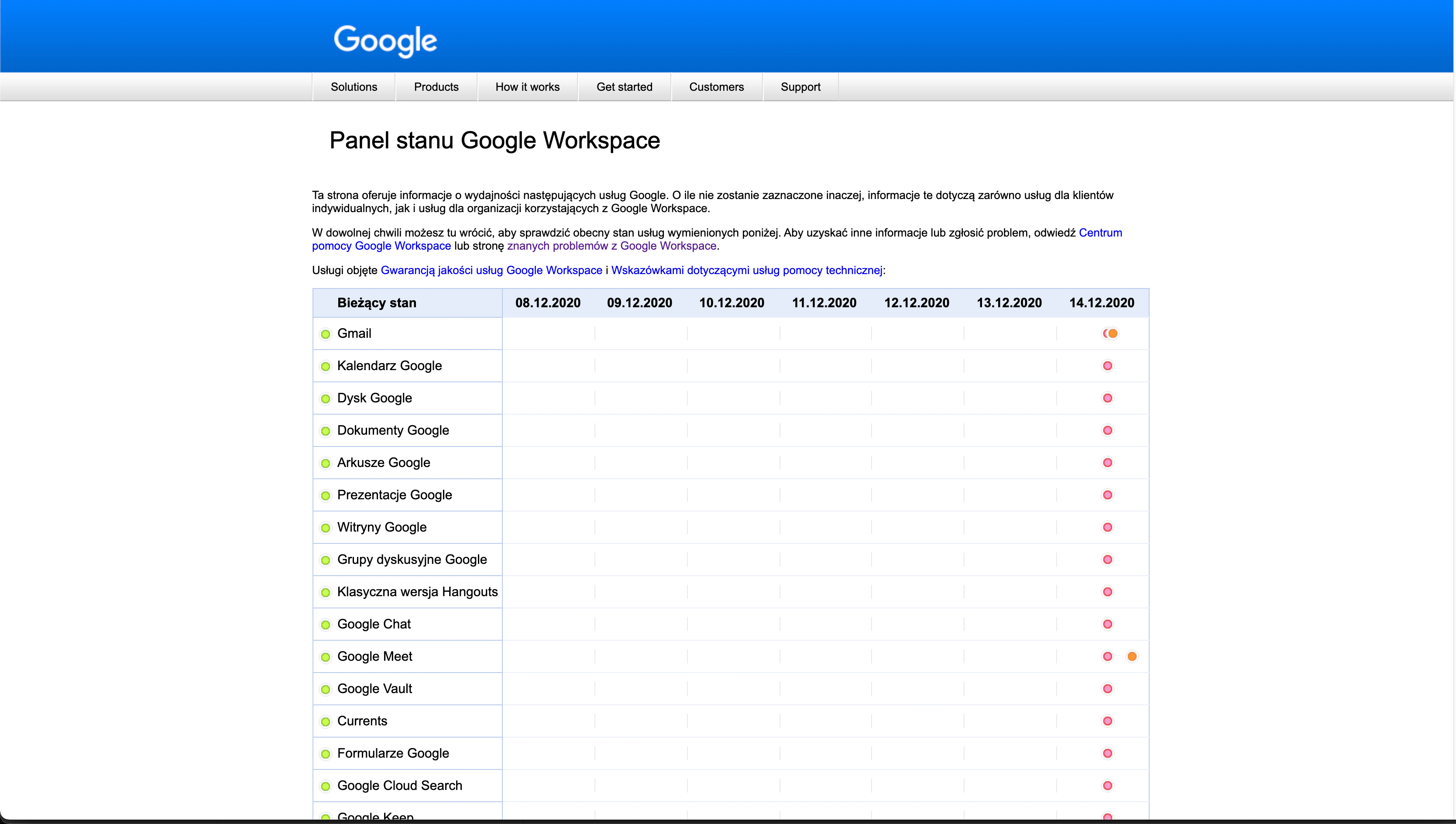
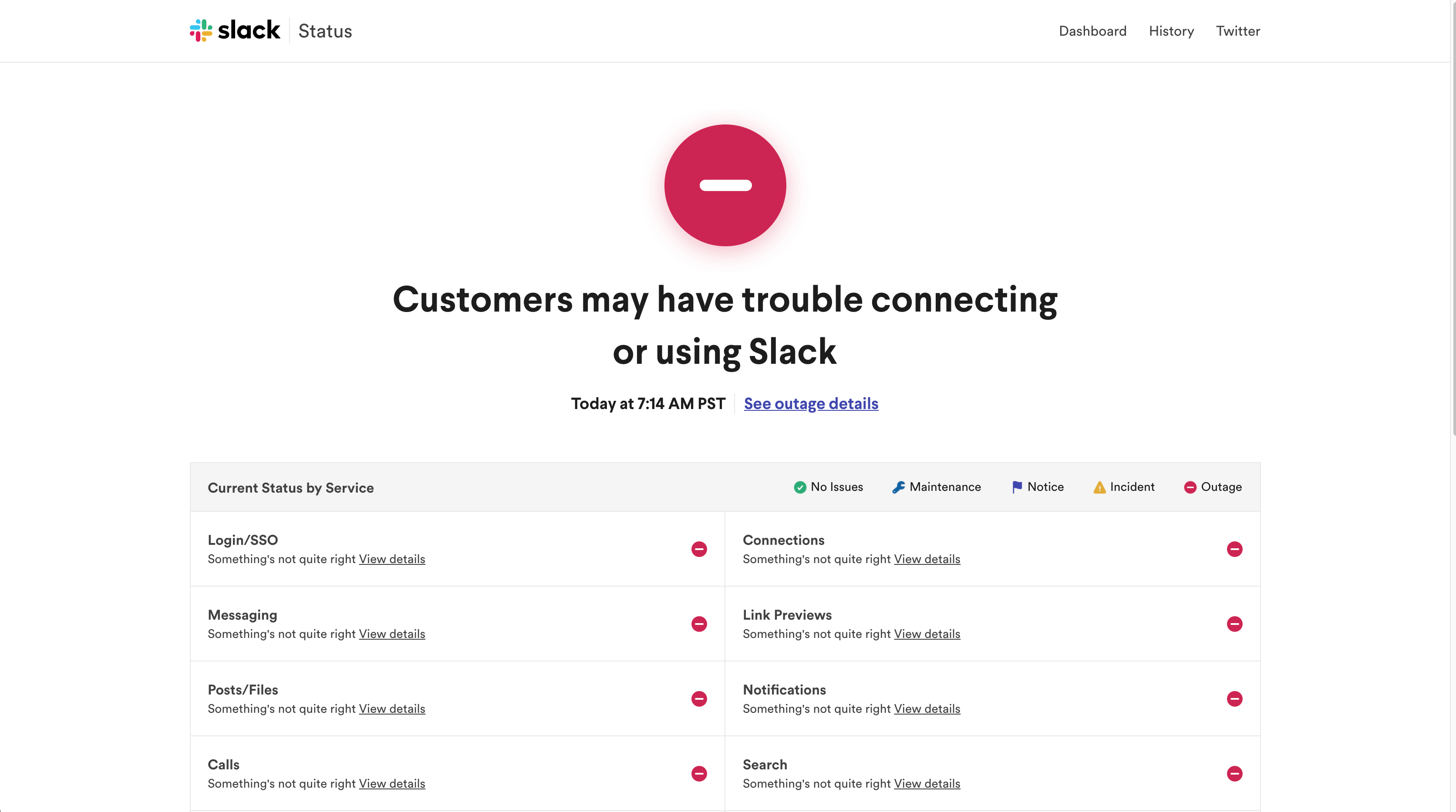
Dobrym rozwiązaniem po każdej awarii jest opisanie co było jej przyczyną oraz jak można zapobiegać takim problemom. Bardzo ciekawie opisuje to na swoim blogu Cloudflare. Ciekawym podejściem do awarii było również udostępnienie live streamingu z prac naprawczych systemu GitLab.
Pożar w data center OVH
Przykładem dużej awarii może być pożar w bloku SBG2 serwerowni OVH w Strasburg. Uszkodził on także blok SGB1, a bloki SGB3 i SGB4 zostały wyłączone dla bezpieczeństwa.




Na spalonych serwerach hostowanych było ponad 3,6 miliona stron internetowych, w tym niszowe platformy rządowe we Francji, Wielkiej Brytanii, Polsce i na Wybrzeżu Kości Słoniowej.
Firmy trzymające kopie zapasowe na tym samym serwerze lub w tym samym data center bezpowrotnie utraciły dane. Dlatego tak ważne jest, aby przechowywać kopie zapasowe serwerów w zupełnie innej i niezależnej lokalizacji.
Podsumowanie
Niezależnie od tego czy jesteś dużym czy małym dostawcą usług związanych z IT musisz przygotować się na incydenty oraz uświadomić swoich klientów na ten temat. Przygotowanie raportu z awarii, odszukanie problemu oraz opisanie procedur zabezpieczających przed ponownym jej wystąpieniem jest wręcz obowiązkowe.
Zobacz podobne artykuły

Jak procedury i checklisty ułatwiają pracę?
Procedury, checklisty oraz spisywanie zadań, towarzyszą mi na każdym kroku: od pracy, hobby przez różne obowiązków. Te trzy niesamowite narzędzia sprawiają, że doba ma więcej godzin, a rzeczy nudne i powtarzalne zaczęły wykonywać automaty, a delegowanie zadań stało się prostsze.

Macierz Eisenhovera, czyli jak zapanować nad priorytetami?
Iść na przerwę a może odpisać na tego maila, czy odebrać telefon od przełożonego? W jakiej kolejności zająć się tymi zadaniami, aby nie utracić nad tym kontroli i nie popaść w bezsilność? Rozwiązaniem tych problemów może być Macierz Eisenhowera (nazywana także Matrycą lub Kwadratem Eisenhowera).

Czy Alert RCB powinien informować o wyborach prezydenckich?
Komunikacja w niebezpieczeństwie jest jednym z ważniejszych zagadnień jakie się porusza podczas żeglowania, latania czy nurkowania. Ostrzeżenia potrafią uratować życie, dlatego nie powinny być lekceważone, a tym bardziej nie powinny swoją treścią prowadzić do ich zignorowania.