Ochrona przed botami AI: Jak zapobiegać scrapowaniu treści?

Generatywna sztuczna inteligencja staje się bardzo popularna, co sprawia, że zapotrzebowanie na nowe treści do generowania modeli, poszybowało mocno w górę. A skąd brać te treści jak nie z dostępnych w sieci stron internetowych? Nie chcesz by ktoś kradł Twoje artykuły czy obrazy? Jest na to kilka sposobów.
Według doniesień, Google płacił rocznie 60 milionów dolarów za licencję na treści generowane przez użytkowników Reddita, a ostatnio Perplexity został oskarżony o podszywanie się pod legalnych użytkowników w celu scrapowania zawartości stron internetowych.
Blokowanie botów AI przed scrapowaniem treści to wyzwanie, które wymaga zastosowania kilku strategii, w tym zarówno prostych jak i zaawansowanych technik. Niestety może się okazać, że nie wszystkie prośby o nie zbieranie danych będą respektowane.
Spis treści
Blokowanie przy pomocy Cloudflare
Najłatwiejszą opcją jest blokowanie takich robotów sieciowych poprzez usługę Cloudflare. Wystarczy w opcjach domeny, którą mamy skierowaną na Cloudflare włączyć blokowanie znanych botów AI.
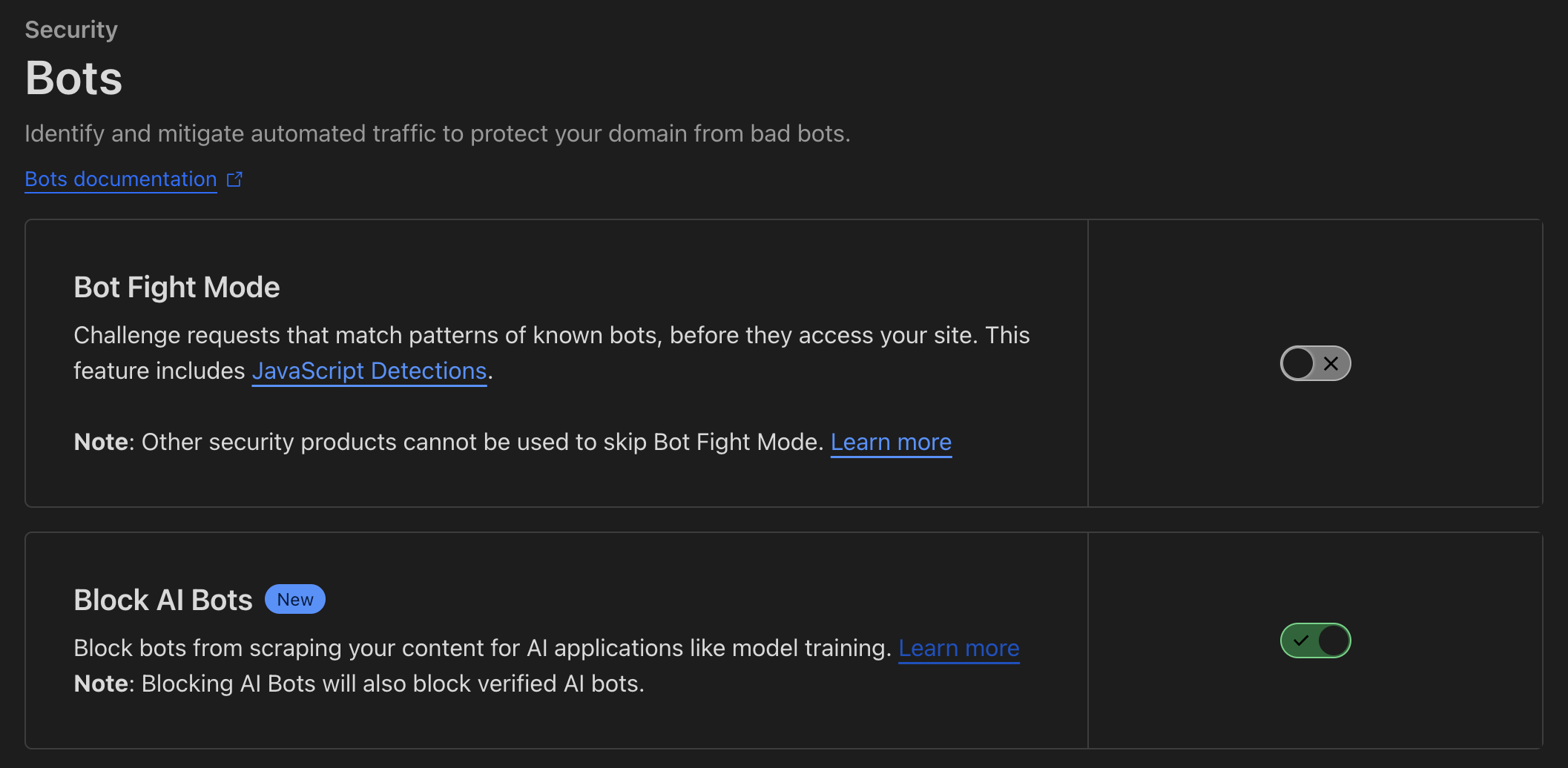
Przechodzimy do sekcji Security > Bots > Block AI Bots i włączamy opcję. Od tego momenty, takie boty nie powinny wchodzić na Twoją stronę i pobierać z niej danych. Więcej na temat tego rozwiązania w artykule Declare your AIndependence: block AI bots, scrapers and crawlers with a single click.
I to rozwiązanie może okazać się jednym z lepszych, ponieważ jak się okazuje, niektóre rozwiązania AI próbują oszukiwać UserAgenta i przedstawiać się inaczej, zatem blokada przez robots.txt mogę okazać się nieskuteczna. Na takim zachowaniu przyłapano np. Perplexity.
Plik robots.txt
To podstawowe narzędzie, które informuje boty, które części witryny mogą indeksować. Możesz dodać do pliku robots.txt wpisy blokujące konkretne boty, np.:
User-agent: AIbot Disallow: /
Należy jednak pamiętać, że plik robots.txt działa tylko na „dobrze zachowujące się” boty, które przestrzegają tych zasad. Niestety są takie boty, które ignorują te ustawienia. Pełną listę botów znajdziesz na https://github.com/ai-robots-txt/ oraz https://darkvisitors.com/.
Blokowanie botów na poziomie serwera
Możesz zablokować boty na poziomie serwera, używając plików konfiguracyjnych takich jak .htaccess (dla serwerów Apache) lub nginx.conf (dla serwerów NGINX). Przykład blokady w .htaccess:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} AI2Bot [NC]
RewriteRule .* - [F,L]
Możesz także blokować określone adresy IP znane z działań związanych ze scrapowaniem. Niestety lista ta się może zmieniać i blokowanie wszystkich podsieci staje się trudne.
Blokowanie dostępu do zasobów publicznych
Ograniczaj dostęp do treści publicznych, np. poprzez wymóg rejestracji lub logowania, a nawet poprzez system subskrypcji. Tego typu treści wymagają zalogowania się lub zakupienia usługi u Ciebie. Niestety są podejrzenia, że takie systemy jak Perplexity, udają prawdziwych użytkowników, by mieć dostęp do tak schowanych treści.
Meta tag noai, noimageai
Meta tag noai jest nowym rozwiązaniem zaprojektowanym specjalnie do zablokowania dostępu dla botów AI, zwłaszcza tych, które zbierają dane w celu trenowania modeli sztucznej inteligencji. Stosowanie tego tagu jest sygnałem dla botów AI, aby nie indeksowały, nie przetwarzały ani nie wykorzystywały zawartości strony internetowej.
Przykładowa składnia tego tagu wygląda tak:
<meta name="robots" content="noai"> <meta name="robots" content="noai, noimageai">
Znaczenie tych atrybutów:
- noai – oznacza dla botów AI, że nie powinny scrapować ani wykorzystywać zawartości strony w swoich działaniach.
- noimageai – oznacza dla botów AI, że nie powinny analizować ani wykorzystywać obrazów z danej strony.
Chociaż ten tag staje się coraz bardziej popularny, jego skuteczność zależy od tego, czy boty AI będą przestrzegały jego wytycznych. Nie wszystkie boty mogą być zaprogramowane do rozpoznawania i respektowania tych metatagów, ale jest to krok w kierunku większej transparentności i ochrony treści przez właścicieli stron internetowych.
Jeżeli będziesz mieć problem z ustawieniem jakieś z tych opcji, skontaktuj się ze mną a na pewno Ci pomogę.
Zobacz podobne artykuły

Awarie IT zdarzają się każdemu
Od paru godzin trwa awaria komunikatora internetowego Slack. Kilka tygodni temu nie można było korzystać z usług firmy Google, a jeszcze wcześniej spora część Internetu nie działała z powodu awarii usług Cloudflare. Czy to możliwe, że usługi w chmurze są niedostępne?

Macierz Eisenhovera, czyli jak zapanować nad priorytetami?
Iść na przerwę a może odpisać na tego maila, czy odebrać telefon od przełożonego? W jakiej kolejności zająć się tymi zadaniami, aby nie utracić nad tym kontroli i nie popaść w bezsilność? Rozwiązaniem tych problemów może być Macierz Eisenhowera (nazywana także Matrycą lub Kwadratem Eisenhowera).

Czy Alert RCB powinien informować o wyborach prezydenckich?
Komunikacja w niebezpieczeństwie jest jednym z ważniejszych zagadnień jakie się porusza podczas żeglowania, latania czy nurkowania. Ostrzeżenia potrafią uratować życie, dlatego nie powinny być lekceważone, a tym bardziej nie powinny swoją treścią prowadzić do ich zignorowania.